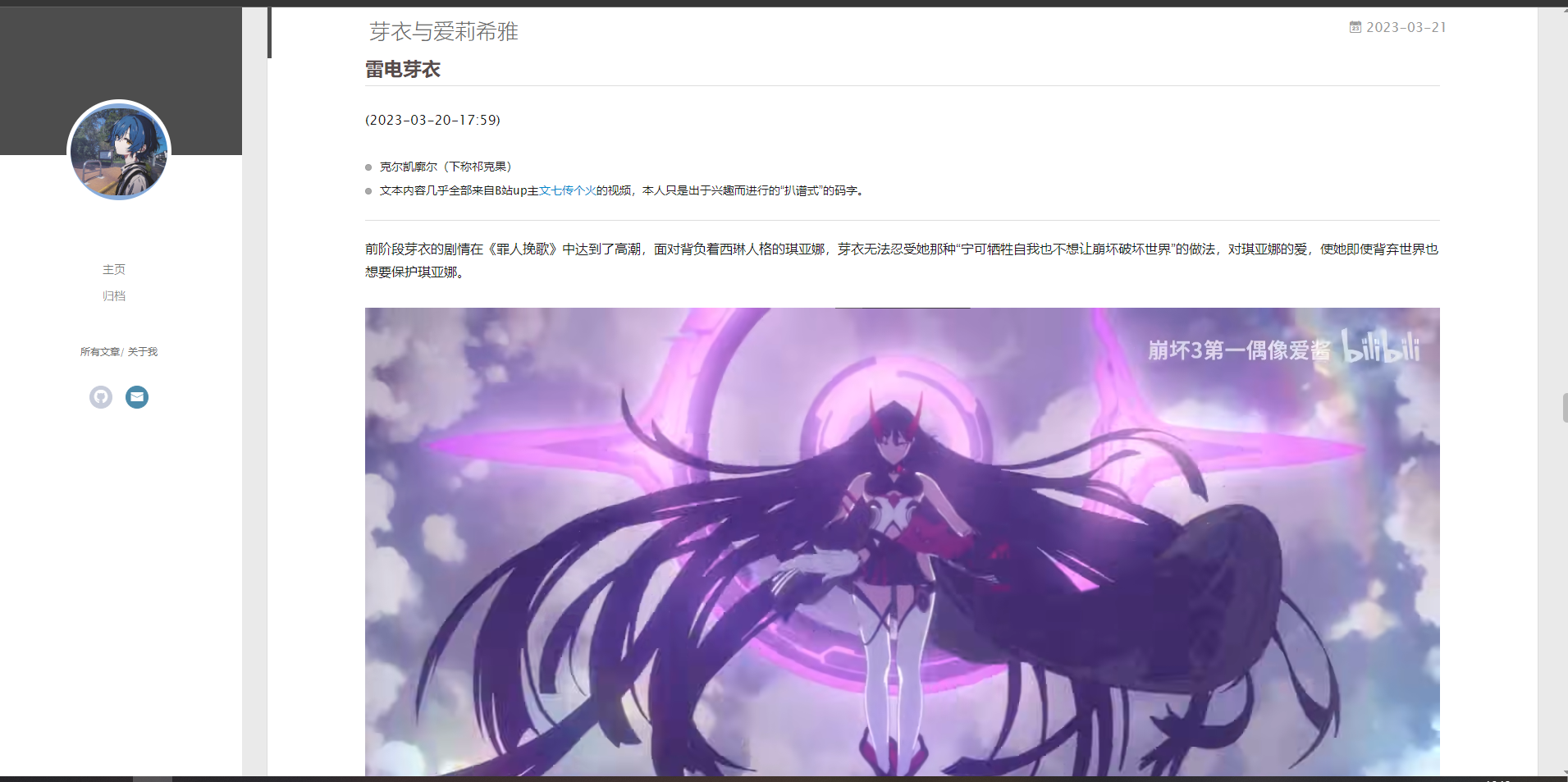
凯文·卡斯兰娜
- 西西弗斯、普罗米修斯、伊卡洛斯
- 文本内容几乎全部来自B站up主文七传个火的视频,本人只是出于兴趣而进行的“扒谱式”的码字。
西西弗斯:徒劳、荒谬
凯文:这个世界早已无法拯救,但我们还是必须成为英雄
西西弗斯面对的是这样一种酷刑:热爱生命与自然,因此反抗了神的约定,于是神惩罚西西弗斯把一块巨石推上山顶,但石头总会因自身重力而滚落下来。这是一种的最可怕的惩罚,用尽全部心力却一无所成。
加缪:登上顶峰的过程足以丰富心灵,西西弗斯应该是幸福的
为什么?西西弗斯神话基于一种结果的无意义,这与加缪的”荒谬“高度相关”。荒谬基于比较,加缪的荒谬注重于两个词:生命、意义。对加缪影响颇深的帕斯卡是这样说的:
帕斯卡:我看到整个宇宙的可怖的空间包围了我,我发现自己被附着在那个广漠无垠的领域的一角,而我又不知道,我何以被安置在这一点而不是另一点,也不知道为何使我得以生存的这一点时间,要把我固定在这一点上,而不是先我而往的全部永恒,与继我而来的全部永恒的另一点上,我看见的只是各个方面的无穷,他把我包围的像个原子。我所明了的一切,就是我很快就会死亡,然后我所最无知的,就是这种我所无法逃避的死亡本身。
这和凯文有什么关系?凯文实际上是“不死的”,但其实凯文的不死与西西弗斯的永恒,就是这种永恒苦难的必要条件。
生命和肉体的荒谬:
总有那么一天,人发现或者说他已经三十岁了,他就这样确定了他的青春,但同时,她也确定了他对时间的位置。他承认自己处于一条曲线的某一点上,而这条曲线他已经表名是要跑完的,他自身归属于时间,从这种恐惧之中,他认出了自己最凶恶的敌人:明天。他希望着明天,但他本应该是拒绝的。肉体的这种的反抗,就是荒诞。
人生而必死,但人们依旧会“反抗”。人就是这样。凯文的处境也是类似。
意义的荒谬:“觉察到世界的厚度”,“江畔何人初见月,江月何年初照人”.MEI;“不是我在仰望星空,而是星空在俯视我。”这是一种视角转换,这种“星空的俯视”依旧是人的自我近观,但是人们还是发现了“一个追求意义的人是如此的渺小”,而相比之下不止意义的巨大的宇宙是如此的庞大。认识到宇宙的无限,人的意义是显得如此渺小。MEI:“尽管如此,每个人还是在有意义的活着”。
加缪:让我们为此最后努力并得出最后的一切结果吧。躯体、温情、创造。行为、人类最后的高贵
那么人们是要刻意去追寻“做不成”的事吗,人应该如何要找到自己要坚持的东西。
注重过程而非结果,这似乎是一种鸡汤。让我们用一种更为贴近生活的比喻:游戏。
游戏实际上是这样两种悖论:胜利的结局实则是失败以及失败的过程实则是胜利:- 当我们最终取得游戏胜利的那一刻,其实标志着游戏的结束,这可以说是一种失败。许多游戏的目标其实并没有意义,球落入网中本身没有任意意义,甚至落入网中那一刻标志的即将到来的下坠。
- 当一个人正视这种无意义的结局并仍然全身心投入时,其过程就构成了意义,甚至包括过程中的失败。
当听到“游戏人生”时,我们应该心生敬畏,因为这是一种对结果无意义的一种漠视和全身心投入其中的一种坦诚。游戏结束后无意义,并不影响丝毫那一瞬间的重要性。
> 伊卡洛斯没有失败。他的坠落是飞行的结果,是另一种胜利的终点。
> 纵然这是一种格局极其狭隘的看法,是浪漫主义者的一厢情愿。
> 这或许是使世界运转的唯一规则。
> 这些一连串没有联系的行动,变成了他的命运,这命运便是由他创造的
只要是人总结出的东西;就一定带有自身的某种局限性,就一定有某种范围,只要超过这种范围,就没有意义。因此,许多的哲学家面对就是这样一种困境。但是,又因为“直面真理”一词听来是如此的具有魅力,以至于让无数思考者前赴后继而不论其意义如何。
> 一个人性格就是他的命运
当我们这重音放在“他的”二字时(性格指什么暂不谈),我们就会意识到,性格塑造的命运,只属于他自己,而非操弄者所摆布的命运。命运因“他”而有意义。这就是整个前文明的精神。
> 加缪的《局外人》:但是在一个突然被剥夺了幻觉和光明的宇宙中,人就感觉到自己是个局外人,这种放逐无可救药。因为人被剥夺了对故土的回忆和对乐土的希望。这种人和生活的分离,演员和布景的分离,正是这种荒诞感。
凯文类似于这样一种局外人。这种局外是相对于上时代的,因为凯文最留恋的事物在上世代,并随上世代消失殆尽。不可否认凯文对现时代的在意很多来自与对MEI,爱莉和其他英杰的承诺。但是凯文却是以实际行动的真心来对待现世界的,无论是在乎现时代人们的理想、愿望,还是那句“最困难的,是放手不管”。
普罗米修斯:希望的火种
普罗米修斯被绑在悬崖之上被鹰鹫啄食内脏,但同时内脏又会不断的长出恢复,由此构成了一种了永恒的折磨。凯文也是如此。符华最终了解了凯文窃取终焉之力的真相:非律者的凯文本身并无法承受终焉之力的力量,因此这种力量无时无刻不在摧毁着凯文。但又因为融合战士的因子,凯文肉身被摧毁的同时不断再生。
那么普罗米修斯窃取的火种又是什么呢?是火种计划,是圣痕计划。这就是凯文“窃取”的火种,将他们保存到了现时代,并仍然相信希望就在其中。这实际上给了西西弗斯无意义结局的一种审视态度:凯文把希望从前世代带到了现时代。而我们每个人,也应以人的历史的视角(而非宇宙)来看待我们每个人的结局,将希望作为我们的意义,将希望传递下去,从而投入我们的生命。这也是所谓“卡斯兰娜”精神的核心。凯文:最初的卡斯兰娜。
伊卡洛斯:鸟为什么会飞
“人类终将战胜崩坏”是凯文带给这个世界的意志,那么凯文又是怎么得出这个意志的呢。
鸟为什么会飞?因为他们不得不飞?不,是因为他们想要飞。鸟对天空的向往没有任何理由,或者说对飞翔的向往本身构成了理由,也构成了意义。此后所有的看似荒谬的行动,都是如此。